Mejoras en el módulo de descripciones
El estado inicial dejó al módulo de descripciones funcionando como una proyección event-driven sobre las tablas mirror, ya descrita en CQRS y Proyecciones. Era un módulo correcto en términos de DDD pero incompleto en dos frentes: la creación de descripciones obligaba al usuario a un segundo viaje (crear el recurso primero, describir después), y la lectura de la tabla central se hacía con un patrón que escalaba mal a medida que crecía el número de descripciones en el sistema.
Este subcapítulo recoge las tres mejoras introducidas durante el TFG sobre el módulo ya existente.
Refactor del catálogo de entidades
El catálogo inicial contemplaba ocho tipos de recurso, entre los que figuraban dos variantes de variable: VARIABLE (variables nativas) y AGGREGATE (variables agregadas, con su fórmula matemática asociada). Esa distinción era útil dentro del módulo de variables, pero dentro del módulo de descripciones era ruido: una descripción es texto sobre un recurso identificado por (entity_id, type_id), y la fórmula matemática de una variable agregada nunca aparecía ni se necesitaba en ninguna consulta del módulo.
Uno de los primeros cambios realizados que detectava cierta inexperiencia en el uso de DDD era el tipo de entidad AGGREGATE-VARIABLE, cuya existencia en el módulo de descripciones estaba en cierta medida incorrecta debido a que un bounded context solo debe conocer lo estrictamente necesario para cumplir su responsabilidad. Y el módulo de descripciones describe; no clasifica. El operador que añade una descripción a una variable agregada lo hace por las mismas razones que la añade a una variable nativa: para explicar qué señal de planta representa. Que internamente una sea agregada y otra no es información que pertenece al módulo de variables, no a este.
El cambio se materializa en una migración sql, V005__remove_aggregate_entity.sql, la cual elimina la tabla mirror de las variables agragads. Por consiguiente los listeners de los eventos AggregateVariableCreated/Changed/Removed reutilizan el mirror único module_description_variable. El consumidor del módulo —el agente RAG y la vista paginada que se describe más abajo— ve un único tipo VARIABLE, y eso es exactamente lo que necesita para hacer su trabajo.
Usando esa misma migración, el segundo cambio efectuado añadió un tipo nuevo, CUSTOMER, en el hueco que dejó libre AGGREGATE (entity_id = 2). La motivación es de producto: cada cliente de DWall necesita poder describir su propia marca —su negocio, su contexto operativo, sus convenciones— para que el agente RAG genere respuestas alineadas con esa identidad. En la práctica funciona como un system prompt personalizable por instalación.
| id | entity | Cambio |
|---|---|---|
| 1 | VARIABLE | ✅ ampliado — absorbe lo que era AGGREGATE |
| 2 | CUSTOMER | 🆕 reemplaza a AGGREGATE |
| 3 | TAG | sin cambios |
| 4 | QUERY | sin cambios |
| 5 | USER | sin cambios |
| 6 | RULE | sin cambios |
| 7 | GROUP | sin cambios |
| 8 | FILE | sin cambios |
En resumen en la tabla podemos observar el cambio en los tipos de recurso efectuados durante este refactor del catálogo.
La descripción como campo opcional del recurso
Antes de esta mejora, el módulo de descripciones operaba como un sistema completamente desacoplado del flujo de creación del recurso. Si un operador daba de alta una variable, una query o una regla, el formulario terminaba con el recurso ya persistido pero sin descripción. Asignar la descripción requería navegar a una vista distinta, buscar el recurso recién creado y rellenar un campo dedicado. El resultado en producción era predecible: la inmensa mayoría de recursos quedaban con descripción vacía, lo que comprometía directamente la utilidad del agente RAG que se nutre de esos textos.
La solución natural es añadir la descripción como si fuera un campo más de cada uno de estos recursos. Lo que significa que dicho elemento deberá existir primero en las tablas nativas de cada recurso.
 Tabla
Tabla variable con la nueva columna description añadida.
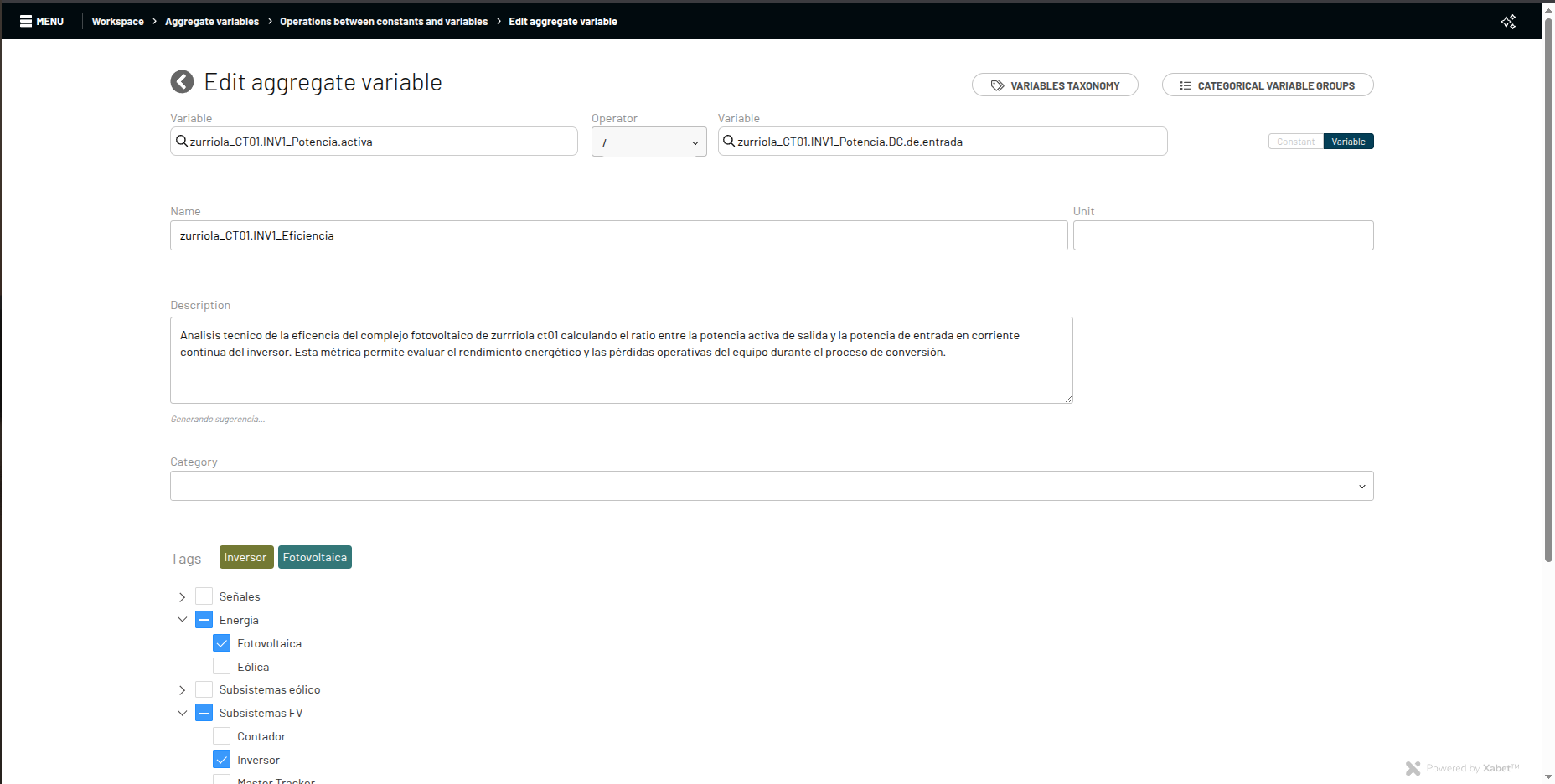 Formulario de alta del recurso incluyendo el campo de descripción.
Formulario de alta del recurso incluyendo el campo de descripción.
Lectura unificada y paginación
Y sin embargo, si se llegara a dar el caso de que el cliente quisiera ver todas las descripciones creadas en el sistema, se ha desarrollado una nueva tabla que da la opción de hacer la lectura unificada con opciones de filtro, ordenación y búsqueda léxica. En resumen, utilizamos componentes frontend ya creados en DWall para representar las descripciones y ser capaces de editarlas fácilmente.
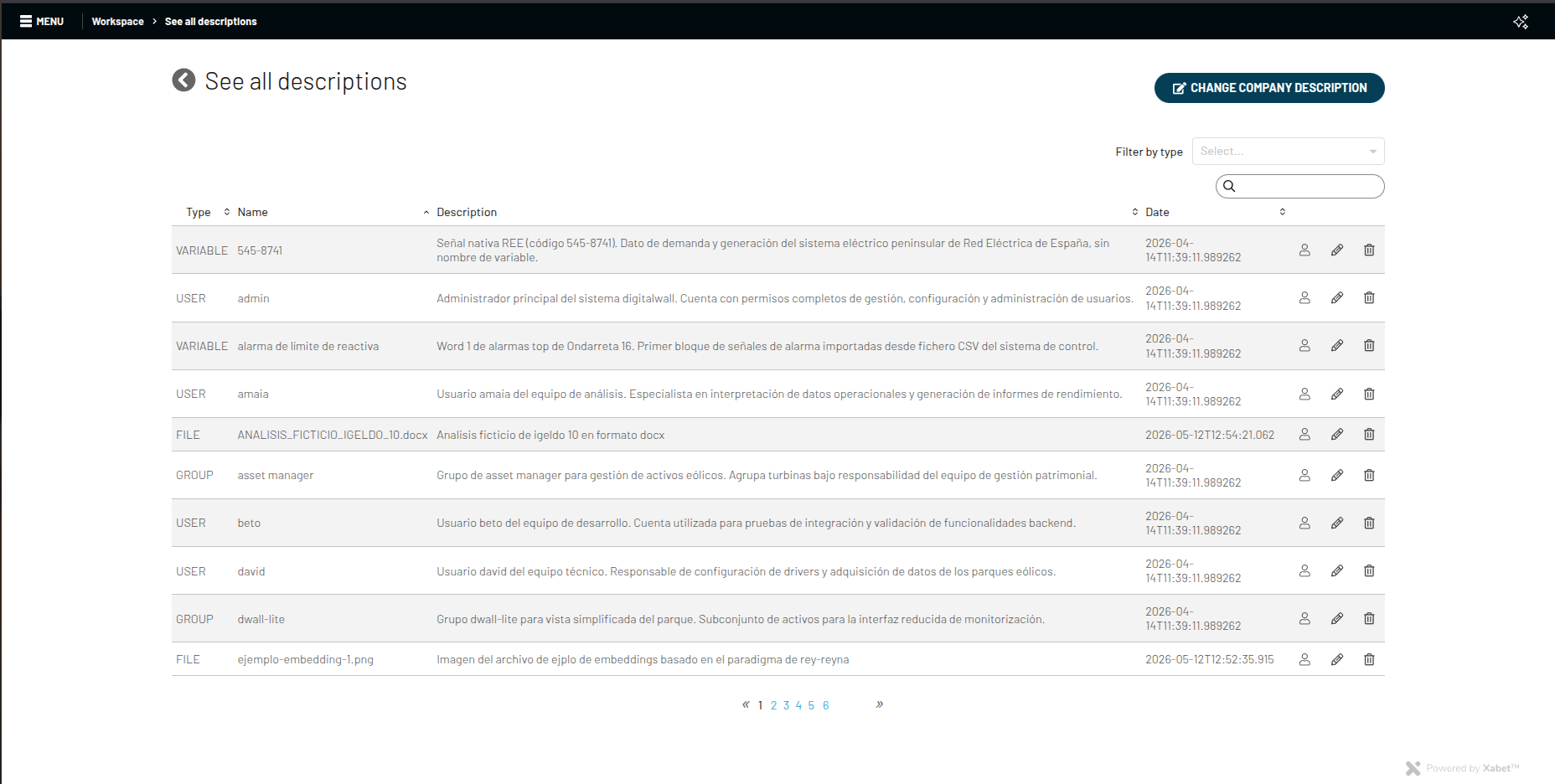 Tabla general de descripciones con filtros y ordenación.
Tabla general de descripciones con filtros y ordenación.
En la anterior imagen observamos la tabla general de descripciones, con un número de opciones de búsqueda totalmente flexibles. Abajo, por otra parte, el formulario de edición de descripciones, el cual únicamente permite modificar estas mismas (los otros campos no son editables por temas de seguridad y arquitectura).
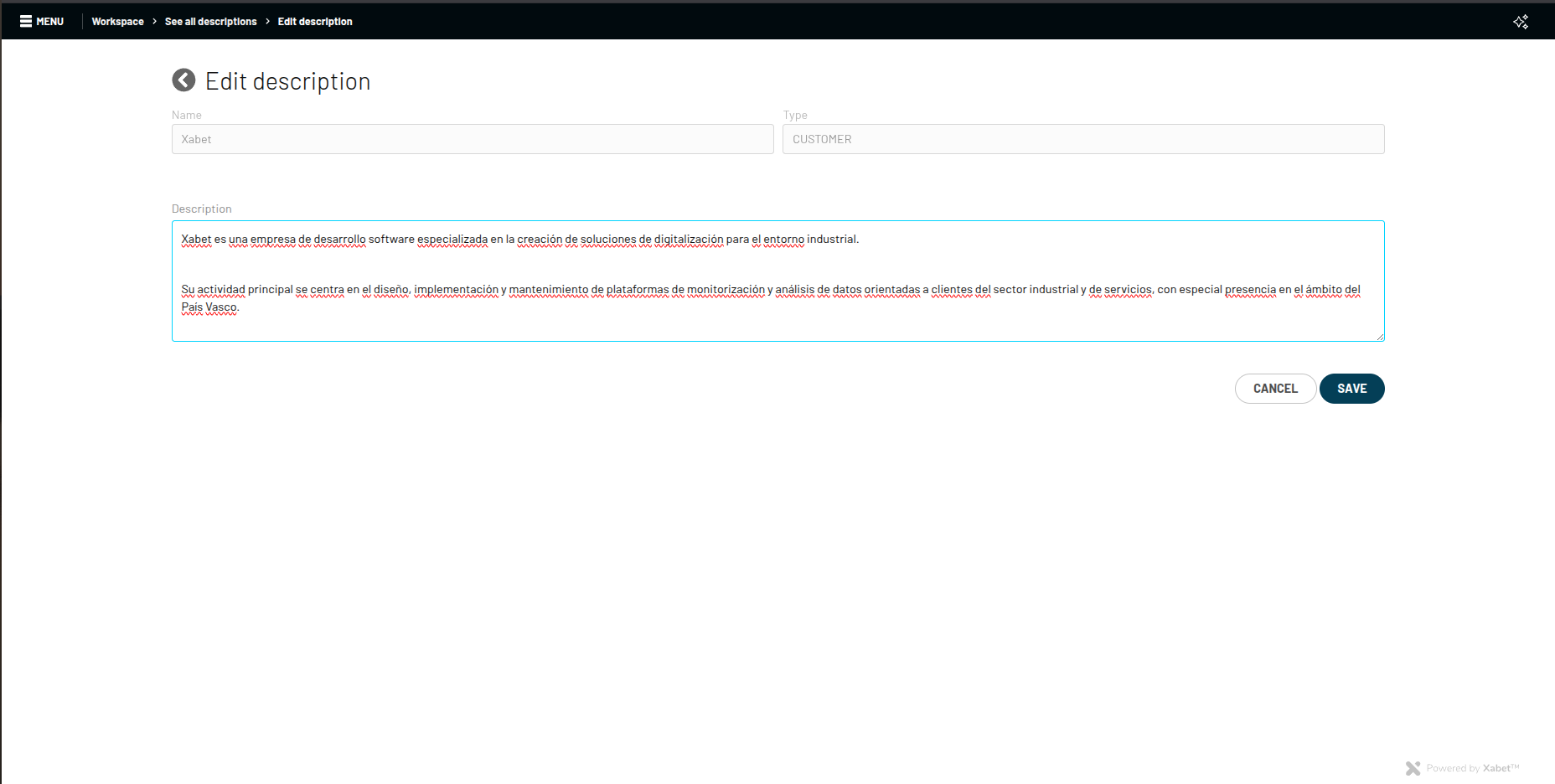 Formulario de edición — solo el texto de la descripción es modificable.
Formulario de edición — solo el texto de la descripción es modificable.
Todo esto en papel parece bastante sencillo de implementar, y pese a que no tiene excesiva complejidad tiene un problema MUY grande: estamos intentando crear una tabla con TODOS los recursos de DWall. Y no solo eso, sino que además lo estamos haciendo mientras intentamos permitir al usuario una cantidad muy flexible de filtros para ordenar o filtrar los archivos.
Para ponernos en contexto, en un servidor local con quizás cientos o pocos miles de recursos sería una práctica muy viable, pero en un entorno de producción donde las cantidades pueden escalar rápidamente es otra cosa. Aquí no podemos ignorar las consecuencias de hacer una consulta sobre cientos de miles de recursos. Por lo que tendremos que paginar nuestras consultas, cosa que sería totalmente automática si la paginación se hiciera a nivel de frontend.
La paginación frontend sería gratuita —cortar un array en JavaScript es trivial— pero exige que ese array exista primero en memoria, y exactamente eso es lo que no podemos permitirnos en producción. La alternativa, paginación backend, traduce el problema en un contrato muy simple: el frontend pide "página X, tamaño Y, con estos filtros y este orden", y la base de datos devuelve exactamente esas Y filas, ni una más. La memoria de la aplicación ni siquiera llega a saber que existen las demás, y la consulta sigue siendo barata por mucho que la tabla central crezca.
Y es justo aquí donde el patrón Criteria —ya analizado en BDV y reutilizado en SPR— enseña su valor con más claridad que en ningún otro sitio del proyecto. Todos los filtros que la tabla del frontend ofrece (tipo de entidad, IDs concretos, texto libre), todas las ordenaciones posibles y la propia paginación caben en un único record del dominio:
public record DescriptionSearchCriteria(
String searchText,
List<Long> entityIds,
List<Long> typeIds,
DescriptionSortField sortField,
SortDirection sortDirection,
int page,
int size) { ... }Sin Criteria, cada combinación de filtro, orden y página obligaría a un método específico en el repositorio o, peor, a concatenar SQL en el servicio. Con Criteria, toda la flexibilidad de la tabla del frontend se traduce a un único objeto opaco que atraviesa controller → service → adapter y se materializa en una sola consulta paginada sobre la vista module_description_named (una vista SQL que precalcula los ocho JOINs hacia las tablas mirror). Añadir un filtro nuevo —por usuario autor, por rango temporal, por longitud mínima— se reduce a un campo más en el record y una condición más en el adapter jOOQ.
El problema N+1 ocurre cuando una consulta inicial devuelve N filas y, por cada una, se dispara una consulta adicional para enriquecerla — total: 1 + N viajes a base de datos. En la versión inicial del módulo, getAllNamedDescriptions cargaba todas las descripciones y, por cada fila, consultaba el mirror correspondiente para resolver el nombre del recurso y el del usuario que la creó. Para 30 descripciones en pantalla, eso suponían 91 round-trips. El Criteria, apoyado en la vista precalculada module_description_named, colapsa todo el trabajo en una sola ida y vuelta.